
Active Linearization Algorithm (ALA) UA-S1010 is a special signal processing tool developed by USound. Here is how ALA can help reduce the THD of MEMS speakers and, as a result, significantly improve the sound quality of audio systems.
How does ALA relate to THD?
Total Harmonic Distortion (THD) is an important parameter for assessing the sound quality of audio products, such as earphones, smart glasses, or loudspeakers. It basically helps assess the non-linearity of a system.
In general, when developing any kind of audio hardware, one of the goals is to reduce the THD in the final product as much as possible to ensure the best sound quality. The overall THD is determined by the “weakest link” in the signal chain; usually this is the speaker. For example, if the speaker produces 1% THD, it doesn’t really matter if the driving electronics have 0.1% or 0.001% THD. That is because the overall amount will be dominated by the non-linear behavior of the speaker. Therefore, the overall THD of any audio product is at least as high as the THD of its speaker.
With USound’s ALA, there are no longer such limitations. Our software tool allows for the overall THD of an audio system to be lower than the THD of the speaker. This is achieved by compensating the non-linearities of the speaker with a carefully tuned algorithm in software, running in real-time on a DSP or general-purpose CPU.
How much can be gained by implementing ALA?
The amount by which ALA can reduce THD varies from speaker to speaker. MEMS speakers are particularly suited for taking advantage of ALA. As an example, the below plot shows measurements on USound’s Conamara 6mm Tweeter, with and without ALA active.
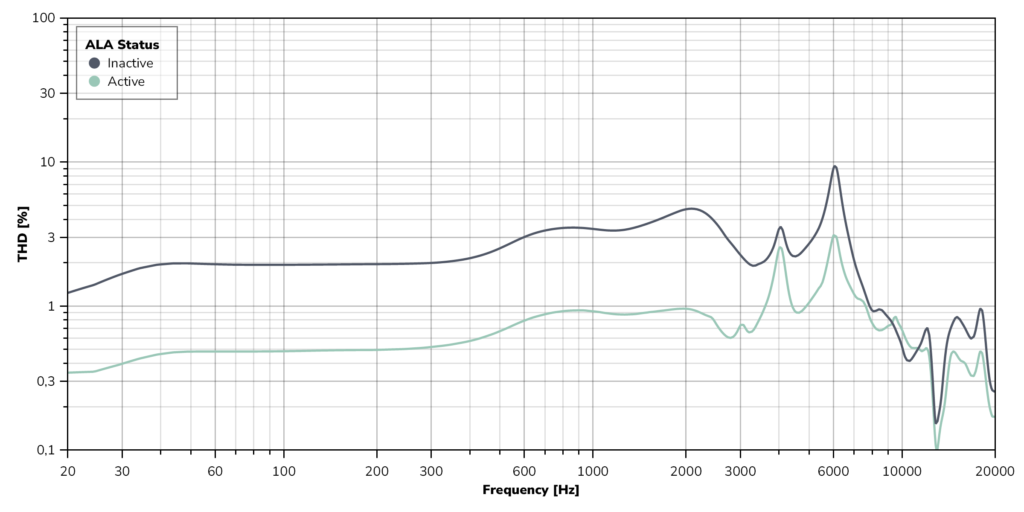
Figure 1: Measurements on USound’s Conamara 6mm Tweeter measured in 711 Coupler at maximum driving voltage (10 V + 10 Vp), with and without ALA active.
How does ALA work?
ALA consists of three main components, which can be used independently from each other:
- Predistortion
The Predistortion compensates static non-linearities of a speaker. This works by knowing and linearizing the characteristic curve. It is very cheap to implement, comparable to a single Biquad filter stage. - Prefilter
The Prefilter improves the performance of ALA at high frequencies. It consists of a pair of Biquad filters. - Hysteresis Model
The Hysteresis Model compensates hysteretic non-linearities of the speaker. It is slightly more expensive to evaluate than the other components, roughly amounting to the equivalent of 6 Biquad filter stages.
For more technical details, of how ALA works, please check out USound’s white paper on ALA.
Note: ALA requires an audio sample rate of at least 96 kHz. If the given audio system runs at a lower sample rate, it is necessary to resample the audio signal before and after the other ALA components are applied. For that purpose, ALA also features an optional resampling component, which is comparably expensive in terms of resources (roughly equivalent to 8-10 Biquad filter stages). This component is not required when the system sample rate is at least 96 kHz.
How is ALA tuned to the characteristics of a loudspeaker?
The underlying algorithms of ALA must have detailed information about the non-linear characteristics of the audio system. This information is obtained by a so-called “training measurement”.
During this measurement, a training signal is played over the audio system and the response is recorded by a microphone. The result of this training measurement is processed offline by a USound proprietary algorithm, which determines the ALA coefficients. These ALA coefficients contain information about the non-linear behavior of the audio system and are used by ALA to compensate non-linearities in real-time, thus reducing the overall THD of the system.
Why does ALA work particularly well for MEMS speakers?
ALA is tuned to a speaker by the ALA Coefficients. For the best THD performance, it is important that the coefficients match the speaker’s characteristics as closely as possible. As it is not feasible to determine ALA coefficients for each single speaker individually, tight manufacturing tolerances during speaker production are crucial for getting good results with ALA. The fully automated processes that are used in the manufacturing process of MEMS speakers allow for a very low part-to-part variation. That means that ALA coefficients (determined based on a training measurement of one particular speaker) will perform well with all other speakers of the same product.
What is needed to implement ALA?
ALA uses a purely software-based method. Therefore, the requirements for implementing ALA in an audio system amount to a processor or DSP with sufficient computational resources available. Here is a list of requirements:
- Direct and real-time access to the stream of audio samples from the firmware running on the processor
- C compiler with support for the processor platform
- Enough computational resources to evaluate ALA
The real-time components of ALA are distributed as a pre-compiled C library. This library can be linked with existing audio firmware.
For additional details, please refer to the ALA Application Note, available on USound’s website.
ALA is now available. Contact our sales department to learn more.
About the Author:
Jonathan Arweck is an acoustic engineer specialized in signal processing and software development. He studied electrical and audio engineering at TU Graz, Austria.